This post shows how to easily implement simple types that wrap strings. This approach has a number of benefits:
The types have domain-specific meaning, so Email and ProductCode (say) are distinct value objects in a domain driven design).
The types cannot be mixed, and if they are, you get type errors at compile time, so Email values cannot be accidentally used where a ProductCode is expected.
The code itself can reveal whether absent values are allowed or not. So for example, a Product ProductCode property can never be null (and if you get it wrong you get errors at compile time), but a ProductCode? parameter could be null in the context of a database query .
String wrappers in F#
Learning functional programming (mainly F#) will change the way you think about writing C# code. There are lot of techniques in F# that, once you understand them, can be back-ported to C#.
In F#, for example, it is trivial to create simple one-liner types that represent simple domain value objects. Here’s the F# code:
Once created, values of these types are distinct and will cause compile time errors if you accidentally mix them up.
12345678
letemail=EmailAddress"abc"letproductCode=ProductCode"abc"// comparison causes error at compile timeletareEqual=(email=productCode)// assignment causes error at compile timeletanEmail:EmailAddress=productCode
(By the way, if you have Visual Studio 2010 or higher, you can test this for yourself in the F# interactive window. Just paste the code in and add a double semicolon at the end of each group)
So we get fine grained domain objects, plus extra type safety at compile time. What’s not to like!
So is there a way of doing this in C#, while keeping it very simple to use?
One obvious way might be to use the F# libraries from C#, and in fact there is a useful library for doing just that.
But for the special case of these simple string wrappers there is a much simpler way, namely using templates to generate the wrapper types as needed.
I have created a T4 template to do just this, and this post will explain how to use it.
/// <summary>/// Struct to wrap strings for DDD, to avoid mixing up string types, and to avoid null strings./// </summary>/// <remarks>/// structs cannot inherit, so the code is duplicated for each. /// </remarks>[Serializable][System.Diagnostics.DebuggerDisplay(@"CurrencyCode[Value]")][System.CodeDom.Compiler.GeneratedCodeAttribute("T4Template:StringWrapper.ttinclude","1.0.0")]publicpartialstructCurrencyCode:IEquatable<CurrencyCode>,IComparable<CurrencyCode>{publicstringValue{get;privateset;}/// <summary>/// Create a new struct wrapping a string./// </summary>/// <param name="str">The string to wrap. It must not be null.</param>/// <param name="transform">A function to transform and/or validate the string. /// The unwrapped string is passed into the transform function, /// and the transform should throw an exception or return null if the string is not valid, // otherwise the transform should convert the string as needed (eg remove spaces, convert to uppercase, etc)./// A null transform is ignored./// </param>/// <exception cref="ArgumentNullException">Thrown if the str is null.</exception>staticpublicCurrencyCodeNew(stringstr,Func<string,string>transform){if(transform!=null){str=transform(str);}if(str==null){thrownewArgumentException("Input to CurrencyCode is not valid","str");}returnnewCurrencyCode{Value=str};}/// <summary>/// Create a new struct wrapping a string./// </summary>/// <param name="str">The string to wrap. It must not be null.</param>/// <exception cref="ArgumentNullException">Thrown if the str is null.</exception>staticpublicCurrencyCodeNew(stringstr){Func<string,string>defaultTransform=s=>{vartrimmed=(s??"").Trim();returntrimmed.Length==0?null:trimmed.ToUpper();};returnNew(str,defaultTransform);}/// <summary>/// Create a new nullable struct wrapping a string, or null if the string is null or invalid./// </summary>/// <param name="str">The string to wrap. If is is null or invalid, null is returned.</param>/// <param name="transform">A function to transform and/or validate the string. /// The unwrapped string is passed into the transform function, /// and the transform should throw an exception or return null if the string is not valid, // otherwise the transform should convert the string as needed (eg remove spaces, convert to uppercase, etc)./// A null transform is ignored./// </param>staticpublicCurrencyCode?NewOption(stringstr,Func<string,string>transform){if(transform!=null){str=transform(str);}if(str==null){returnnull;}returnnewCurrencyCode{Value=str};}/// <summary>/// Create a new nullable struct wrapping a string, or null if the string is null./// </summary>/// <param name="str">The string to wrap. If is is null, null is returned.</param>staticpublicCurrencyCode?NewOption(stringstr){Func<string,string>defaultTransform=s=>{vartrimmed=(s??"").Trim();returntrimmed.Length==0?null:trimmed.ToUpper();};returnNewOption(str,defaultTransform);}publicoverridestringToString(){returnValue;}publicoverrideboolEquals(objectother){returnotherisCurrencyCode&&Equals((CurrencyCode)other);}publicboolEquals(CurrencyCodeother){returnValue.Equals(other.Value,StringComparison.InvariantCulture);}publicoverrideintGetHashCode(){returnValue.GetHashCode();}publicstaticbooloperator==(CurrencyCodelhs,CurrencyCoderhs){returnlhs.Equals(rhs);}publicstaticbooloperator!=(CurrencyCodelhs,CurrencyCoderhs){return!lhs.Equals(rhs);}publicintCompareTo(CurrencyCodeother){returnString.CompareOrdinal(Value,other.Value);}}/// <summary>/// Extensions to convert strings into CurrencyCodes./// </summary>publicstaticclassCurrencyCodeStringExtensions{/// <summary>/// Create a new struct wrapping a string./// </summary>/// <param name="str">The string to wrap. It must not be null.</param>/// <param name="transform">A function to transform and/or validate the string. /// The unwrapped string is passed into the transform function, /// and the transform should throw an exception or return null if the string is not valid, // otherwise the transform should convert the string as needed (eg remove spaces, convert to uppercase, etc)./// A null transform is ignored./// </param>/// <exception cref="ArgumentNullException">Thrown if the str is null.</exception>publicstaticCurrencyCodeToCurrencyCode(thisstringstr,Func<string,string>transform){returnCurrencyCode.New(str,transform);}/// <summary>/// Create a new struct wrapping a string./// </summary>/// <exception cref="ArgumentNullException">Thrown if the str is null.</exception>publicstaticCurrencyCodeToCurrencyCode(thisstringstr){returnCurrencyCode.New(str);}/// <summary>/// Create a new nullable struct wrapping a string, or null if the string is null or invalid./// </summary>/// <param name="str">The string to wrap. If is is null or invalid, null is returned.</param>/// <param name="transform">A function to transform and/or validate the string. /// The unwrapped string is passed into the transform function, /// and the transform should throw an exception or return null if the string is not valid, // otherwise the transform should convert the string as needed (eg remove spaces, convert to uppercase, etc)./// A null transform is ignored./// </param>publicstaticCurrencyCode?ToCurrencyCodeOption(thisstringstr,Func<string,string>transform){returnCurrencyCode.NewOption(str,transform);}/// <summary>/// Create a new nullable struct wrapping a string, or null if the string is null./// </summary>publicstaticCurrencyCode?ToCurrencyCodeOption(thisstringstr){returnCurrencyCode.NewOption(str);}}
Here’s a screenshot from Visual Studio:
Using the new type
You can now create instances of this type, either using the static New method, or the helper methods that have been defined.
For example, say that we have a method BuySomething:
1234567
voidBuySomething(ProductCodeproductCode,decimalprice,CurrencyCodecurrencyCode){if(productCode==null){thrownewArgumentNullException("productCode");}if(currencyCode==null){thrownewArgumentNullException("currencyCode");}Console.WriteLine("Bought {0} for {1}{2}",productCode,price,currencyCode);}
First, the new type is a struct not a class, which means that it cannot be null.
Which in turn means that the null checks that litter most C# code are not needed – you are not allowed to pass nulls as arguments, and you will get a compiler error if you try.
12345
// try with null productBuySomething(null,12.34m,usd);// Result is a compiler error:// Argument 1: cannot convert from '<null>' to 'ProductCode'
So BuySomething can be rewritten to be cleaner:
1234
voidBuySomething(ProductCodeproductCode,decimalprice,CurrencyCodecurrencyCode){Console.WriteLine("Bought {0} for {1}{2}",productCode,price,currencyCode);}
Second, the compiler’s static type checking will stop you accidentally getting the parameters in the wrong order:
123456
// try with product and currency swappedBuySomething(usd,12.34m,product1);// Result is a compiler error:// Argument 1: cannot convert from 'CurrencyCode' to 'ProductCode' // Argument 3: cannot convert from 'ProductCode' to 'CurrencyCode'
In one fell swoop you have (a) eliminated code for runtime error-handling code and (b) guaranteed extra levels of correctness. Isn’t that nice.
Transformation and validation
Often, a domain type will have rules about what values are valid for that type. For example example.com would be a valid DomainName but not a valid EmailAddress.
And even if the string is valid, it might need to be transformed into a canonical form, such as being uppercased, or having spaces replaced with hyphens.
The template allows you to customize this transformation and validation by having variants that allow a function or lambda to be passed in.
The simple rule is that if the function returns a null, the input is not valid.
So for example, here is a function for email addresses that validates against a regex and lowercases the input if successful:
1234567891011121314151617181920
publicpartialstructEmailAddress{publicstaticstringTransformEmailAddress(stringstr){if(string.IsNullOrWhiteSpace(str)){returnnull;}conststringpattern=@"^[A-Z0-9._%-]+@[A-Z0-9.-]+\.[A-Z]{2,4}$";if(Regex.IsMatch(str,pattern,RegexOptions.IgnoreCase)){returnstr.ToLower();}//add logging//Console.WriteLine("The string '{0}' is not a valid email address", str);returnnull;}}
The generated code is created in a partial struct, so that you can easily add custom behavior like this in a separate file.
You can use this function explictly when creating values:
One of the advantages of this approach is that there is a clear distinction between when the value is optional and when it is not.
For example, for an interface to a product database, you might have something like this:
123456789
interfaceIProductRepository{ProductGetByCode(ProductCodeproductCode);/// <summary>/// Find all matching. Note that productCode and supplierCode are optional but currencyCode is not./// </summary>IEnumerable<Product>FindMatchingProducts(ProductCode?productCode,SupplierCode?supplierCode,CurrencyCodecurrencyCode);}
By using nullables, the interface itself makes it explicit when the product code is required (for GetByCode) and when it optional (for FindMatchingProducts).
And this requirement is enforced by the compiler itself.
To see the importance of this, here is the same interface using strings:
123456789
interfaceIProductRepository{ProductGetByCode(stringproductCode);/// <summary>/// Find all matching. Note that productCode and supplierCode are optional but currencyCode is not./// </summary>IEnumerable<Product>FindMatchingProducts(stringproductCode,stringsupplierCode,stringcurrencyCode);}
With this interface you must look at the comments to know what is required or not – the compiler will not enforce it for you.
And if you get it wrong, you will not know immediately, but only at runtime (assuming you added null checking for the required parameters!)
Creating optional values
So how do you go about creating optional values? Simply use the NewOption static method on the struct or the ToXXXOption extension method.
12
varc="".ToCurrencyCodeOption();Assert.IsNull(c);
The same transform and validation functions can be used, but in this case, a failed validation will result in a null value for the type.
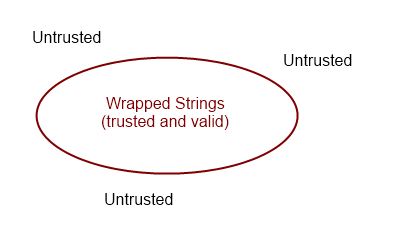
Using this approach in conjunction with a validation boundary
By wrapping the strings and enforcing validation at creation time, we have shifted the work from the consumers of the type to the creators of the type.
In other words, without using this technique, the implementor has to do all the validation:
12345678910111213
// caller codevaremailAddress="BADSTRING";EmailService.SendEmail(emailAddress)// implementors codeclassEmailService{publicvoidSendEmail(stringemailAddress){if(emailAddress==null){thrownewArgumentNullException(...);}if(!IsValid(emailAddress)){thrownewArgumentException(...);}// do work}
But with this technique, the caller has to do the validation upfront, and the implementation is easier:
123456789101112131415
// client codevare="BADSTRING".ToEmailAddressOption();if(e!=null){EmailService.SendEmail(emailAddress.Value)}// implementors codeclassEmailService{publicvoidSendEmail(EmailAddressemailAddress){// no validation needed// do work}
So in some sense, we haven’t really eliminated the work, but just moved it somewhere else. This is indeed true. But you might think of this technique as part of a general “validation boundary” approach around the core domain code. Inside the boundary, everything is valid and safe, and outside the boundary it is a wild jungle. When potentially dangerous data from the UI or database comes into the system, the boundary is where the validation occurs, rather than in the core.
So, for example, an MVC web app would create these kinds of wrapped strings in the controller before passing them to the domain model.
A database access or persistence layer would do the same thing, although if the persisted value was invalid on load, you might need to support two different domain types – such as ValidEmailAddress and InvalidEmailAddress. See the related post on union types for an example of how to deal with this.
Issues with this approach
There are a couple concerns that seem to arise when using this approach.
First, it’s not totally idiot proof. You can still create invalid objects if you want to. For example, the following code will create a CurrencyCode with a null string.
1
varc=newCurrencyCode();
There is not much we can do about this, unfortunately – it’s in the nature of structs. But hopefully this would not happen too often, and overall I prefer the usefulness of having non-null structs to having normal classes.
Second, you might also have performance concerns about using structs rather than classes, as they may need to be boxed and unboxed. In this particular case, I doubt that that much conversion will be happening in practice. But my general response to all concerns about performance is that you should rely on facts rather than assumptions.
For example, in my code that uses this approach, I haven’t seen any performance hits, but if your profiler tells you that the app is slow because of too much boxing and unboxing, then by all means, don’t use this approach. However, I think that in many (if not most) cases the benefits of correct code will outweigh any performance decrease.